
Grouping the Feed: From Raw Topics to Usable Structure
In the last post, I added a thin AI layer on top of a Mastodon feed, generating summaries and topics for each post.
That was a useful step. It made the feed easier to scan and started to introduce structure.
The next step felt like a natural extension: if each post has topics, can those topics be used to group posts in a meaningful way?
From topics to structure
The idea seemed straightforward.
If each post has a set of topics, then grouping posts by those topics should give us some structure:
- post → topics
- topics → groups
In practice, it didn’t quite work that way.
What the first attempt looked like
In the initial version, the pipeline looked like this:
- fetch posts from Mastodon
- clean the content
- send each post through the AI layer
- use the returned topics directly for grouping
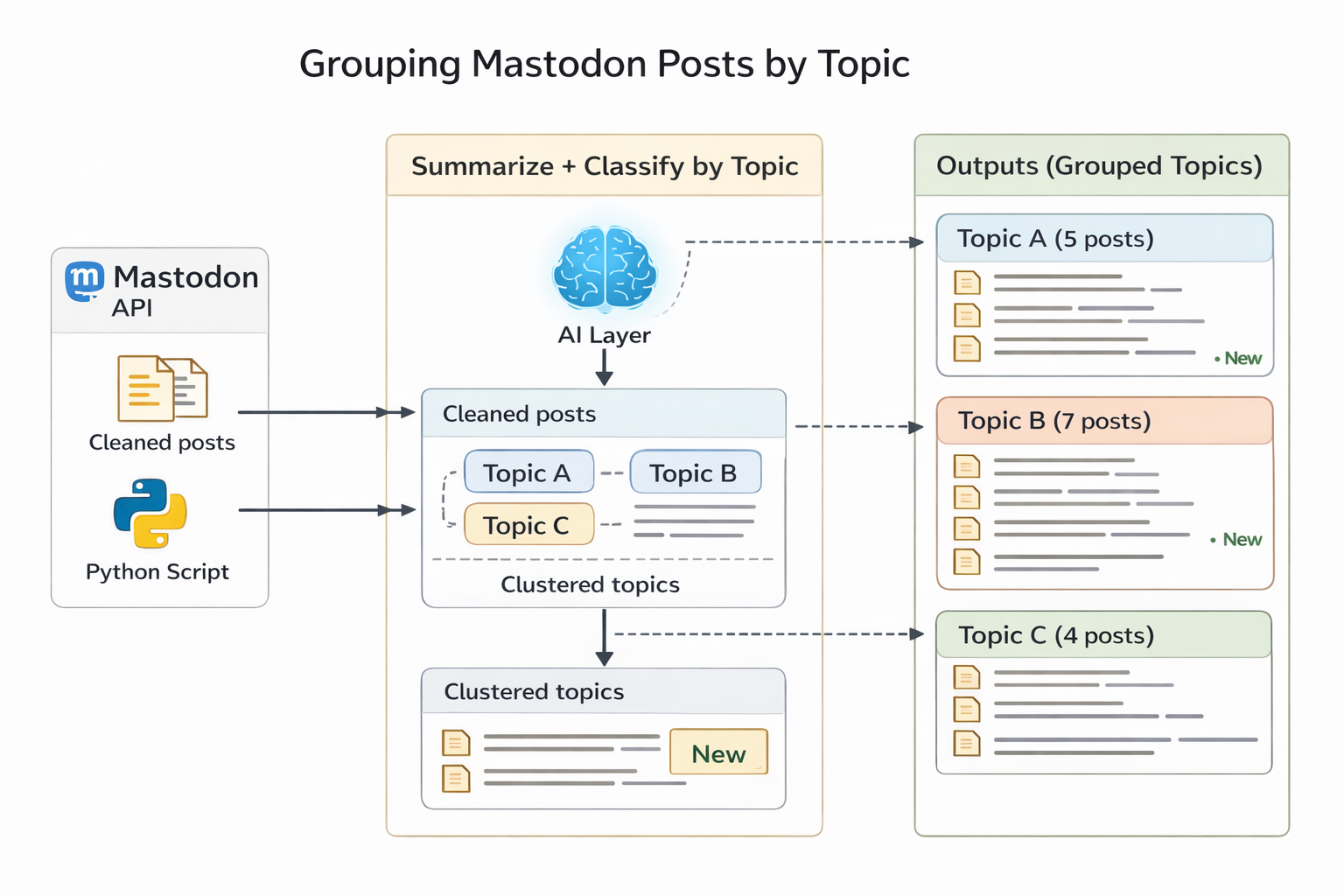
Initial direction: a compact pipeline where the AI layer handled most of the semantic work directly.
At this stage, the model was responsible for both:
- interpreting the content
- producing labels that would implicitly act as grouping keys
That worked up to a point, but it also revealed a problem.
The problem: too many topics, not enough structure
When I ran the grouping step, I ended up with:
- a large number of topics
- most topics containing only one post
Technically, everything was working. But the result wasn’t very useful.
Instead of meaningful clusters, I got a long list of loosely related labels.
The issue wasn’t grouping logic.
The issue was the type of topics being generated.
The model was producing topics that described individual posts very well, but those topics weren’t always reusable across posts.
For example:
- “Elon Musk Litigation”
- “Distribution Specific Installation”
- “Creativity And Liberation”
These are accurate descriptions, but they are too specific to function as grouping categories.
That changed the shape of the problem.
Evolving the architecture
At this point, it became clear that the system needed a separation of responsibilities.
Instead of relying on the AI layer to do everything, I split the pipeline into two distinct stages:
- the AI layer generates summaries and raw topic candidates
- a rules-based Python layer normalizes those topics and groups posts deterministically
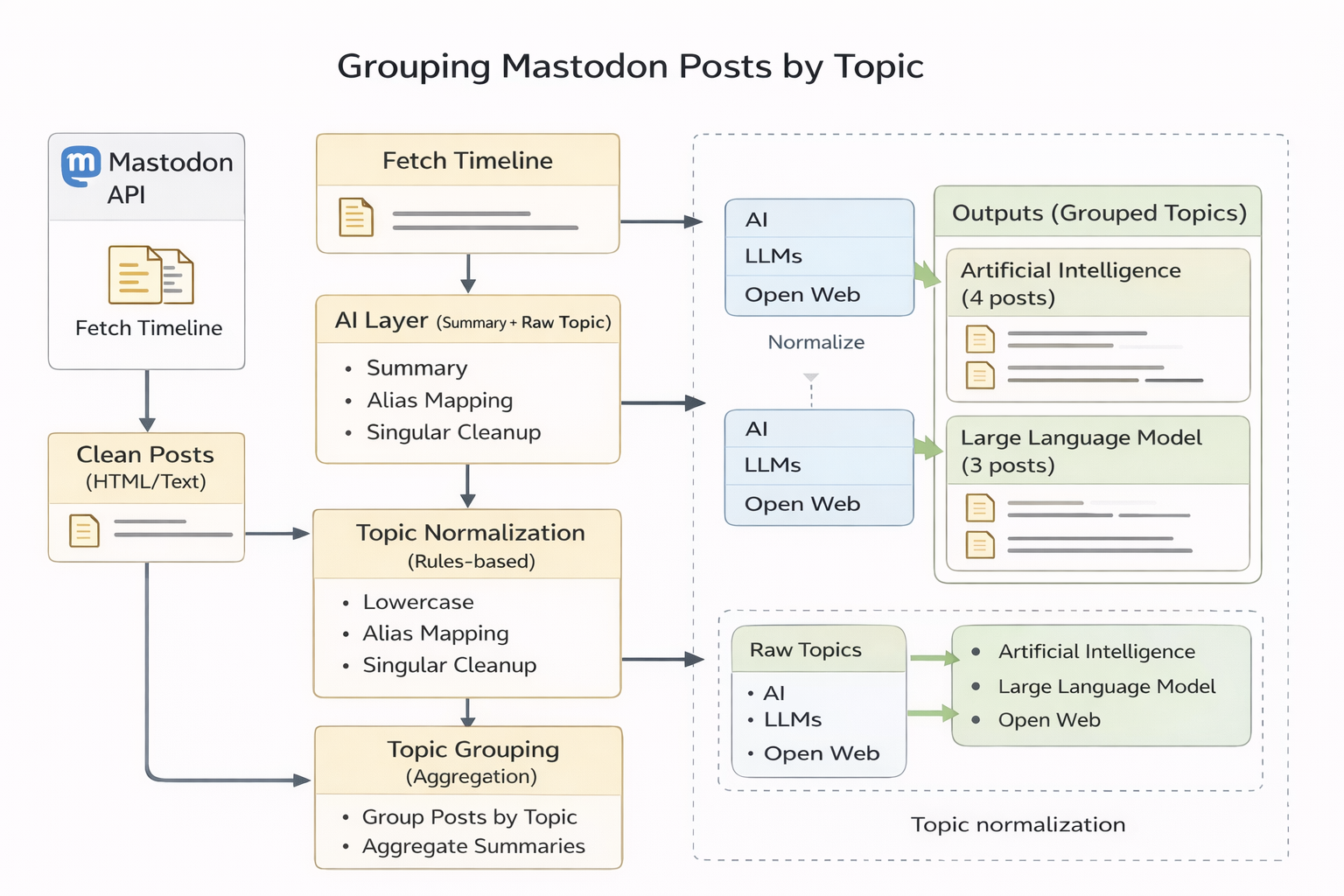
Updated architecture: the AI layer generates candidate structure, while normalization and grouping are handled explicitly in Python.
This is a small change structurally, but an important one conceptually.
The model is good at suggesting meaning, but the system still needs explicit rules for consistency.
What changed in this iteration
The architecture stayed the same in this pass. The focus was on improving how topics are generated and how they are used.
Fewer, broader topics
Instead of asking for 3–5 topics per post, I now ask for 2–3.
More importantly, the prompt emphasizes reusable categories rather than detailed descriptions.
The goal is to produce labels that can apply across multiple posts, not just describe one.
Topic normalization in Python
Even with a better prompt, topic labels still vary.
For example:
- “LLMs” vs “Large Language Models”
- “APIs” vs “API”
- “Models” vs “Model”
To handle this, I added a normalization step in Python.
This includes:
- lowercasing
- trimming whitespace
- simple alias mapping (e.g.
llms → large language model) - light singular/plural cleanup
This is intentionally simple. The goal is not perfect linguistic normalization, but consistent grouping keys.
Filtering weak groups
Finally, I added a simple rule:
Only display topics that have at least two posts.
This removes noise and makes the output easier to scan.
If a topic only appears once, it’s not really a group.
Structured outputs
One practical detail that made this easier to work with is the use of structured outputs.
Instead of asking the model to return free-form text, the prompt explicitly requests a JSON object with two fields:
summarytopics
That looks like this:
{
"summary": "...",
"topics": ["...", "..."]
}
Using a structured format has a few advantages:
- the output is predictable
- parsing is straightforward
- downstream logic becomes simpler
In this setup, the model isn’t just generating text. It’s acting as a transformation step that maps unstructured input into structured data.
That makes it much easier to plug into a pipeline like this one.
A quick look at the Python side
Each post is represented as a dictionary:
{
"author": "...",
"content": "...",
"summary": "...",
"topics_raw": [...],
"topics_normalized": [...]
}
Grouping with dictionaries
To group posts by topic, I use a dictionary where:
- the key is the topic
- the value is a list of posts
For example:
{
"artificial intelligence": [post1, post2],
"machine learning": [post2, post3],
}
A useful helper for this pattern is defaultdict:
from collections import defaultdict
grouped = defaultdict(list)
A defaultdict(list) automatically creates an empty list when a new key is accessed, which simplifies grouping logic.
Filtering with dictionary comprehensions
After grouping, I filter out weak clusters:
def filter_topic_groups(grouped, min_posts=2):
return {
topic: posts
for topic, posts in grouped.items()
if len(posts) >= min_posts
}
This uses a dictionary comprehension, which is a concise way to construct a new dictionary from an existing one.
What the output looks like now
With these changes:
- fewer topics overall
- more posts per topic
- clearer patterns across the feed
The output is still simple, but it’s starting to become useful.
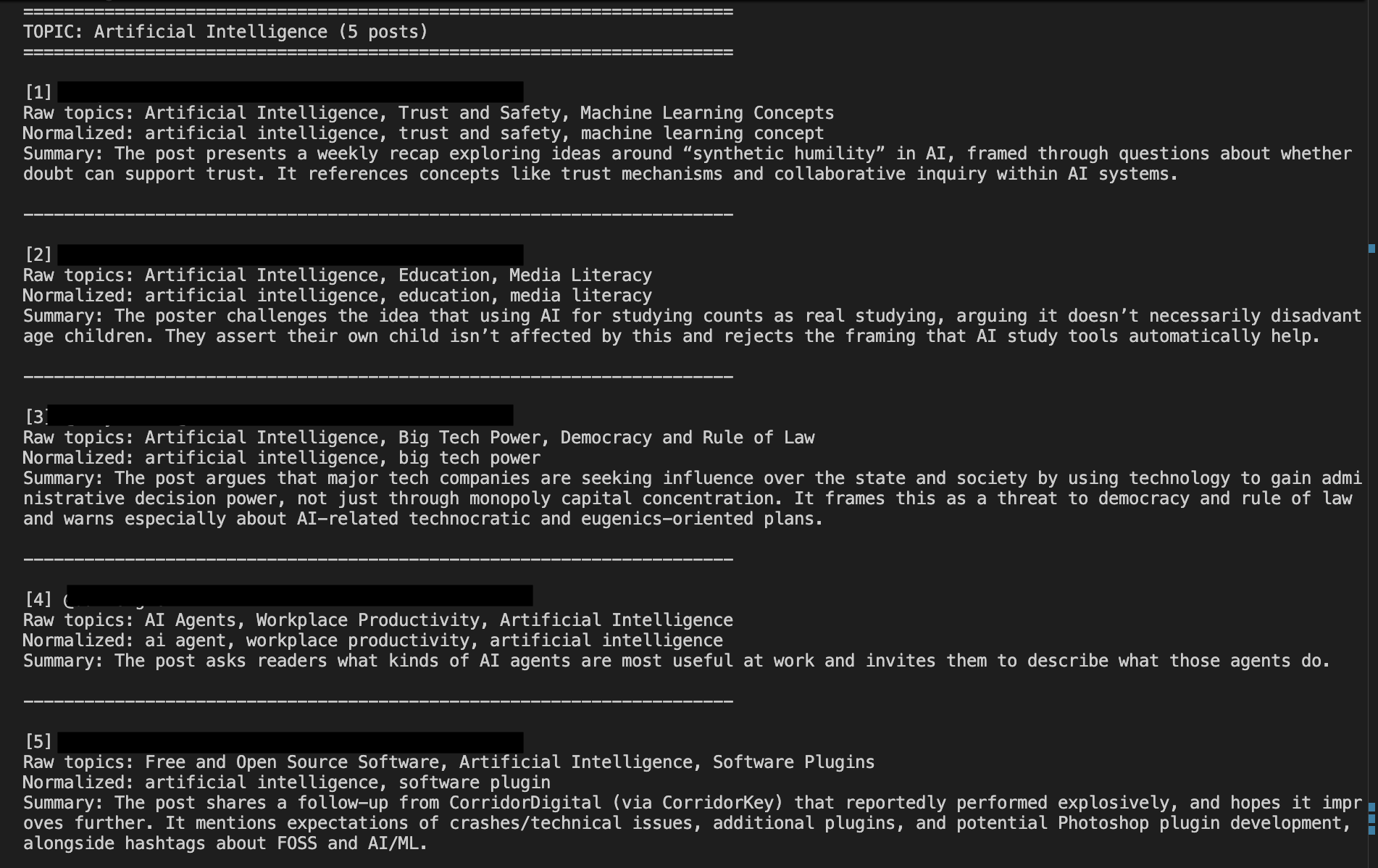
Output showing broader, reusable topic groups with clearer clustering across posts.
What this changes conceptually
The system is no longer trying to extract a perfect set of topics from each post.
Instead, it does two things:
- generates candidate structure (AI layer)
- enforces consistency (Python layer)
That separation makes the system easier to reason about and easier to improve.
What’s next
The next step is to move beyond simple grouping and start looking at relationships across posts.
Some directions to explore:
- merging similar topics into broader clusters
- generating summaries for entire topic groups
- identifying recurring themes over time
At that point, the system starts to move closer to something that resembles a semantic layer on top of the feed.
Closing
The first version of grouping technically worked, but it made the limitation clear: describing posts is not the same as organizing them.
This iteration focuses on that distinction.
By making topics more reusable and grouping more deliberate, the system starts to move from raw output toward structure.
Code: ai-feed-lens on Codeberg
topic-groupingTag:
post-04-topic-grouping